聯邦學習(Federated Learning, FL)使多個用戶能夠協作訓練高精度全局模型,同時保護用戶的數據隱私。然而,聯邦學習容易受到惡意參與者發起的拜占庭攻擊。盡管該問題已引起廣泛關注,但現有的防御算法存在一些缺陷:即使在前幾輪檢測到惡意用戶后,服務器仍會非理性地選擇惡意用戶進行聚合;防御算法在數據異構場景無法有效抵御女巫攻擊。為此,我們提出了聯邦學習魯棒性聚合算法MAB-RFL。通過將用戶選擇建模為擴展的多臂老虎機(Multi-Armed Bandit, MAB)問題,我們提出了一種自適應用戶選擇策略,以選擇更有可能提供高質量更新的誠實用戶。然后,我們提出了兩種方法來識別來自女巫和非女巫攻擊的惡意更新,基于這些方法可以準確評估每個用戶選擇決策的獎勵以阻止惡意行為。MAB-RFL在對潛在良性用戶的探索和利用之間取得了令人滿意的平衡。大量的實驗結果表明,MAB-RFL在各種攻擊以及攻擊者比例下均優于現有防御。
該成果“Shielding Federated Learning: Robust Aggregation with Adaptive Client Selection”被CCF列表A類國際會議International Joint Conference on Artificial Intelligence (IJCAI 2022)錄用為Long Oral Presentation。IJCAI是人工智能領域國際頂級會議,2022年Long Oral Presentation的錄用率僅有3.75%。

- 論文鏈接:https://www.ijcai.org/proceedings/2022/0106.pdf
背景與動機
聯邦學習是近年來興起的分布式架構,其旨在保護用戶數據隱私的前提下實現分布式數據的聯合訓練。由于訓練過程中用戶和中心服務器僅需交換模型參數,而用戶的源數據始終保持在本地,因此用戶隱私得到了較好的保護。然而聯邦學習極易遭受拜占庭攻擊,即攻擊者可以上傳惡意模型參數使得最終的聚合結果偏離正常模型甚至留下后門。
為了抵御拜占庭攻擊,研究人員提出了一系列防御算法。它們的核心思想包括:根據相似性剔除離整體分布較遠的參數;利用統計特性剔除或者繞開惡意參數;對模型參數進行裁剪從而降低惡意參數對聚合結果的影響;使用干凈數據集對模型參數的性能進行檢驗。
雖然現有防御種類豐富、數量龐大,但它們普遍存在以下的短板,導致其很難部署到實際應用中。第一,它們忽略了用戶選擇的重要性。現有防御要么選擇所有用戶,要么隨機選擇一部分用戶參與訓練,前者會帶來巨大的通信開銷,而后者則會造成模型收斂速度慢、準確率低;第二,它們無法有效應對女巫攻擊,在女巫攻擊場景下所有惡意參數極度相似或者完全相同,而現有防御的傾向于剔除離整體分布較遠的參數,這會造成正常參數被剔除;第三,現有防御在數據異構場景表現不佳,因為數據異構會導致正常參數之間也存在巨大差異,給檢測帶來極大困難;第四,現有防御效果較好的方案往往依賴于與用戶數據分布相同的驗證數據集,這明顯違背了聯邦學習保護用戶隱私的初衷。
為了解決這些問題,我們提出了首個基于多臂老虎機的聯邦學習魯棒性算法MAB-RFL。該算法將聯邦學習中的用戶選擇問題建模為擴展版的多臂老虎機問題,使得中心服務器能夠自適應地選擇那些有較高概率貢獻良性參數的用戶。在應用現有的多臂老虎機問題解決方案到聯邦學習場景之前,我們需要解決兩個挑戰。第一,在標準的多臂老虎機問題中,每輪只有一個臂被選中,然而在聯邦學習場景,每輪需要選擇多個用戶來保證模型的高精度以及收斂速度。受湯普森采樣算法的啟發,我們將用戶的期望獎勵視為該用戶被選擇的概率,中心服務器基于概率動態地選擇當前輪次的參與者;第二,在標準的多臂老虎機問題中,一旦玩家選擇一個臂,老虎機會自動反饋相應的獎勵,然而在聯邦學習中,服務器需要對每一次用戶選擇進行評估并完成獎勵分配。為此我們提出了兩個檢測算法分別檢測女巫攻擊和非女巫攻擊,并基于檢測結果為用戶分配獎勵。
方案設計
我們提出的MAB-RFL主要包含自適應用戶選擇、女巫攻擊檢測、非女巫攻擊檢測、獎勵分配四個關鍵步驟。
自適應用戶選擇:在標準的湯普森采樣算法中,每次只會選擇平均獎勵(由Beta分布估計)最大的臂。將其擴展到聯邦學習的一種直覺想法是選擇平均獎勵排名前m(m為良性用戶數量)的用戶。然而,這依賴于一個假設,即良性用戶的數量是固定并且被服務器所知。這個假設是不現實的,因為聯邦學習是一個動態分布式網絡,其中誠實和惡意的用戶可以隨意退出。
為了擺脫對m的依賴,我們提出以動態變化的概率選擇用戶(即,概率隨著每個用戶過去的表現而變化,而不是使用固定的概率)。具體而言,用戶k被選擇概率為pk←Beta(Bk,Mk),其中Bk和Mk分別表示用戶k過去表現正常和惡意的輪次(由下面的女巫攻擊檢測和非女巫攻擊檢測模塊判斷)。
該算法可以達到利用(Exploitation)和探索(Exploration)的良好平衡。具體來說,如果一個用戶總是持續貢獻良性更新(即Bk大而Mk小),則該用戶會從Beta(Bk,Mk)獲得一個較大被選概率pk(利用);如果一個用戶每次參與聯邦學習都貢獻惡意更新(即Mk大而Bk小),則該用戶會得到較小的pk(利用);如果一個用戶很少被選擇(Bk和Mk都很小),該用戶依然有可能獲得較大的pk(探索),因為當參數Bk和Mk均很小時,Beta分布的方差較大。
女巫攻擊檢測:女巫攻擊的主要特性為惡意更新兩兩之間非常相似,甚至比正常更新之間的相似度更高,因此現有基于離群值檢測的防御算法容易出現誤識別。基于這一特性,我們提出使用最大連通子圖策略來檢測女巫攻擊。具體而言,我們將每個上傳到服務器的本地更新視為一個節點(vertex),并根據如下規則構造一個無向圖:若更新 和
和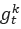 滿足
滿足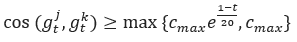 ,則在節點j和k之間添加一條邊。上式中cos表示余弦相似度,超參數cmax和cmin分別為預估的最大和最小的正常更新相似度,t表示當前輪次。可以看到,隨著迭代的進行,可容忍余弦相似度(不等式右邊)越來越小,這也意味著攻擊者越來越難發起隱蔽的女巫攻擊。
,則在節點j和k之間添加一條邊。上式中cos表示余弦相似度,超參數cmax和cmin分別為預估的最大和最小的正常更新相似度,t表示當前輪次。可以看到,隨著迭代的進行,可容忍余弦相似度(不等式右邊)越來越小,這也意味著攻擊者越來越難發起隱蔽的女巫攻擊。
在構造好無向圖后,該圖的最大連通子圖中的節點(本地更新)將被識別為惡意更新并被剔除。女巫攻擊檢測過程如圖1所示。
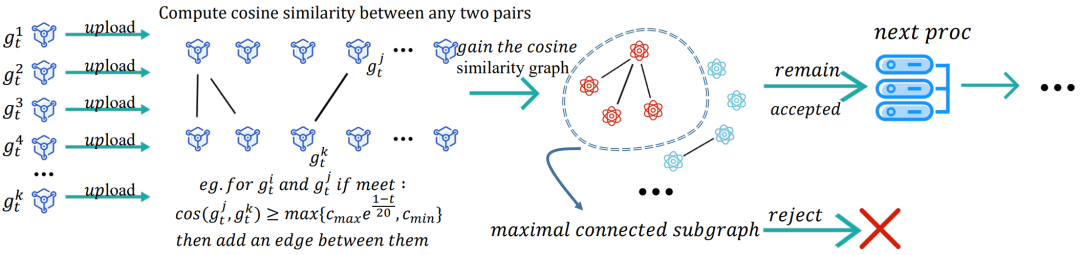
圖1 女巫攻擊檢測
非女巫攻擊檢測:在非女巫攻擊場景,惡意更新彼此之間差異較大,檢測它們極其困難。其關鍵原因在于本地更新的維度極高,其中既包含關鍵性的特征,同時也包含掩蓋正常與惡意更新之間差異的冗余信息。此外,聯邦學習固有的數據異構特性導致正常更新之間的差異也較大,因此發現惡意更新變得更加困難。鑒于此,我們的主要想法是提取關鍵特征,在易于區分的低維特征空間剔除惡意更新。另外,我們引入動量機制,來降低本地更新之間的方差,從而構造一個類似于同構的分布。具體而言,我們的算法包含如下三個步驟:
- 計算動量向量:
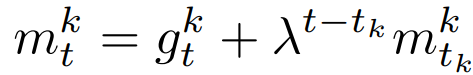 ,其中λ∈(0,1)表示歷史信息的重要程度,tk表示用戶k上一次被選的輪次;
,其中λ∈(0,1)表示歷史信息的重要程度,tk表示用戶k上一次被選的輪次; - 使用主成分分析法(PCA)提取每個動量向量的關鍵特征;
- 對關鍵特征使用層次聚類算法將動量向量分為兩個簇,并將較小簇中的更新視為惡意更新并剔除,然后聚合較大簇中的動量向量用于更新全局模型。
獎勵分配:一個合理的獎勵分配機制對于MAB-RFL降低惡意用戶被選概率極為關鍵。在女巫攻擊和非女巫攻擊識別出惡意更新后,我們將對應用戶的獎勵設為0,即Mk←Mk+1。對于通過這兩個檢測模塊的更新,我們將對應用戶的獎勵設為1,即Bk←Bk+1。
實驗評估

圖2 LF攻擊下性能對比
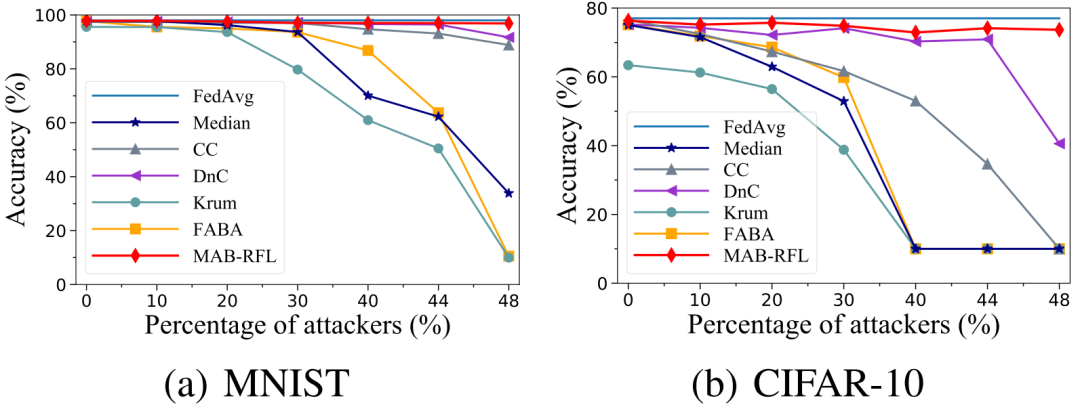
圖3 LIE攻擊下性能對比
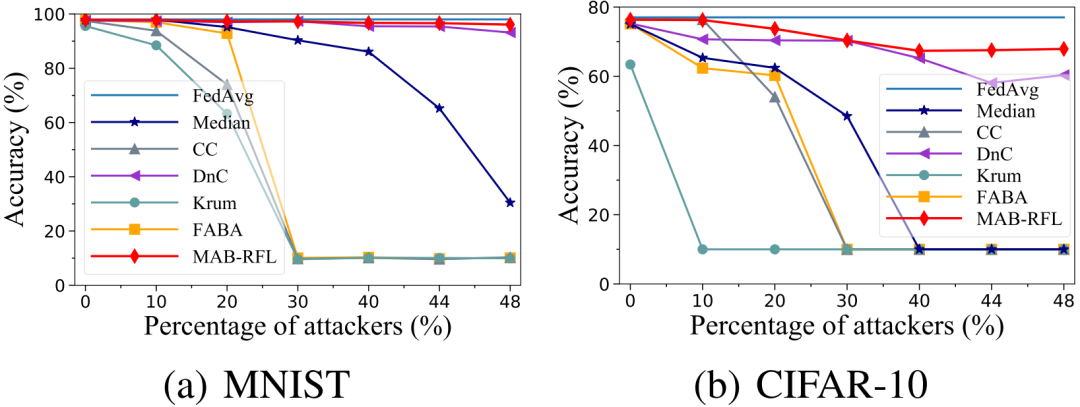
圖4 AGRT攻擊下性能對比
我們使用多個魯棒性聚合算法作為基線,在MNIST和CIFAR-10數據集上,對MAB-RFL的有效性進行評估。我們考慮了三種不同知識強度的攻擊,即LF攻擊、LIE攻擊和AGRT攻擊。其中LF為零知識攻擊(攻擊者不知道正常用戶的更新和服務器部署的聚合算法),LIE為部分知識攻擊(攻擊者只知道正常用戶的更新但不知道服務器部署的聚合算法),AGRT為全知識攻擊(攻擊者同時知道正常用戶的更新和服務器部署的聚合算法)。如圖2、圖3、圖4所示,在各種攻擊以及攻擊者比例下,MAB-RFL的模型精度均高于現有防御策略,且攻擊者比例越高其優越性越明顯。相對于現有最先進的DnC防御,我們的準確率最多可提升33%。
詳細內容請參見:
Wei Wan, Shengshan Hu, Jianrong Lu, Leo Yu Zhang, Hai Jin, Yuanyuan He, “Shielding Federated Learning: Robust Aggregation with Adaptive Client Selection”, in Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence (IJCAI), 2022, pp. 753-760.
https://www.ijcai.org/proceedings/2022/0106.pdf
 黑白之道
黑白之道
 公安部網安局
公安部網安局
 SecPulse安全脈搏
SecPulse安全脈搏
 安全牛
安全牛
 黑白之道
黑白之道
 GoUpSec
GoUpSec
 GoUpSec
GoUpSec
 D1Net
D1Net
 D1Net
D1Net
 黑客技術和網絡安全
黑客技術和網絡安全
 信息安全與通信保密雜志社
信息安全與通信保密雜志社
 中國信息安全
中國信息安全
